本文介绍了Deep High-Resolution Representation Learning for Human Pose Estimation的一些基础内容。
这个姿势估计算法源自Simple Baselines,两者在这统称 SimplePose.
本文简要对SimplePose的原理和网络结构点到为止,主要记录了官方实现框架的基本结构、Bug、使用和改造技巧,并附带了一些姿势估计的基础内容。
Paper:
Deep High-Resolution Representation Learning for Human Pose Estimation
Simple Baselines for Human Pose Estimation and Tracking
github:
Resnet版本-human-pose-estimation.pytorch
HRNet版本(同时也包含Resnet实现)-deep-high-resolution-net(推荐,工具更完善,本文以此为例)
安装
Refs to the git repo README
conda env activate <your env>
pip install -r requirements.txt
cd lib
make
install cocoapi
download coco dataset from oneDrive to
./data/coco/annotations
./data/coco/images
download pretrained model from oneDrive
SimplePose
是一个属于top-down方式的姿势估计算法,前面一般需要接一个目标检测器。
其网络结构非常简单,前面是Resnet提取特征,紧接着接两层Deconvolution。
如果是HRNet提取特征,则最后简单接一层final_layer,得到网络输出。
HRNet-W32/W48,32和48表示stage的通道数。
网络的输出是[N,C,W,H],比如[1,17,64,48],表示batchsize=1,17个关键点热力图(heatmap)。
heatmap的尺寸默认是64x48,heatmap尺寸跟最终接的Deconvolution的个数有关。
heatmap是一个高斯分布(gaussian),heatmap中的最大值(>0)所处的位置就是关键点的坐标。
COCO数据格式
https://cocodataset.org/#download(COCOAPI)
https://cocodataset.org/#format-data
https://blog.csdn.net/hjxu2016/article/details/110629987
说明
annotations、categories、images都是一个list,每一项都包含一个id。
annotations通过image_id与images关联,通过category_id与categories关联。
annotations:
"keypoints"(关键点的坐标和属性,总数==3*关键点个数,x,y,v)
v 为 0 时表示这个关键点没有标注(这种情况下 x=y=v=0)
v 为 1 时表示这个关键点标注了但是不可见(被遮挡了)
v 为 2 时表示这个关键点标注了同时也可见。
num_keypoints:实际标注了关键点个数,000的关键点不计算在内
bbox:目标框,(x,y,w,h)
categories:
"keypoints"(关键点名称)
"skeleton"(关键点的关联性)
images:
"file_name": "000000406417.jpg",,图片名称,代码中会从train2017/val2017中读取
"height": 640,图像的尺寸
"width": 568,
关键点评估指标
OKS:计算两套关键点的相似度,一套是groudtruth,一套是预测的结果。
OKS使用多个维度信息进行度量:
- 关键点距离d;
- 面积信息s;
- 标注的离散程度sigma(d/s的期望);
- 数据总量delta
Test
为了简单,修改数据集中的 person_keypoints_val2017.json,只保留一张图像。
python tools/test.py --cfg experiments/coco/resnet/res50_256x192_d256x3_adam_lr1e-3.yaml
AssertionError: Invalid device id
根据设备实际情况,修改yaml的GPUS配置。
最终结果:
=> writing results json to output/coco/pose_resnet/res50_256x192_d256x3_adam_lr1e-3/results/keypoints_val2017_results_0.json
Loading and preparing results...
DONE (t=0.00s)
creating index...
index created!
Running per image evaluation...
Evaluate annotation type *keypoints*
DONE (t=0.00s).
Accumulating evaluation results...
DONE (t=0.00s).
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.000
Average Recall (AR) @[ IoU=0.50 | area= all | maxDets= 20 ] = 0.000
| Arch | AP | Ap .5 | AP .75 | AP (M) | AP (L) | AR | AR .5 | AR .75 | AR (M) | AR (L) |
|---|---|---|---|---|---|---|---|---|---|---|
| pose_resnet | 0.000 | 0.000 | 0.000 | -1.000 | 0.000 | 0.000 | 0.000 | 0.000 | -1.000 | 0.000 |
output\coco\pose_resnet\res50_256x192_d256x3_adam_lr1e-3目录下得到几张图片,包含了gt.jpg pred.jpg.
效果图:

关键点识别挺准,但图像缩放得不对,这是因为变换时先将图像放大到1.25倍,且是等比例缩放,导致人体目标附近附带其它无关内容。
详情见下方提到的仿射变换。
特定场景快速验证
目的是快速校验在项目场景上的识别效果
创建数据集目录
mydata/
└── coco
├── annotations
│ └── person_keypoints_demo2017.json
└── images
├── demo2017
│ ├── 000000000111.jpg
│ └── 000000406417.jpg
└── val2017
└── 000000406417.jpg
- person_keypoints_demo2017.json 来自 person_keypoints_val2017.json,内部只包含添加测试的图片
- cp experiments/coco/resnet/res50_256x192_d256x3_adam_lr1e-3.yaml demo/
修改yaml文件:
DATASET:
COLOR_RGB: false
DATASET: 'coco'
ROOT: 'mydata/coco/'
TEST_SET: 'demo2017'
python tools/mytest.py --cfg demo/res50_256x192_d256x3_adam_lr1e-3.yaml
同样,在输出目录中得到输出验证结果。
经过本人测试,50x120分辨率的人像,识别效果还不错。具体到项目中,还需对测试数据进行标注后,才能得到较全面的测试结果。
关键点标注方法
https://github.com/jsbroks/coco-annotator
这个工具安装比较麻烦。
得到实际场景的效果,或者需要进行优化时,这样做:
- 获取多样性、代表性的测试集
- 标注数据(将本程序改造一下,自动生成关键点及其标注文件)
- 计算OKS
SimplePose仿射变换
框架中有两种仿射变换,一是图片的缩放和裁剪(图像的仿射变换),二是关键点的重定位(关键点的仿射变换)。
图像的仿射变换流程:
coco.py -> __getitem__ -> utils.transforms.py -> get_affine_transform -> cv2.warpAffine
首先mark一下,scale的计算故意放大了25%,这么做的原因未知:
def _xywh2cs(self, x, y, w, h):
if center[0] != -1:
scale = scale * 1.25 #改成1.0切图更准确
图解仿射变换
计算原图中的三个点(三角形),以及目标图中对应的三个点,再通过cv2.getAffineTransform获得变换矩阵。
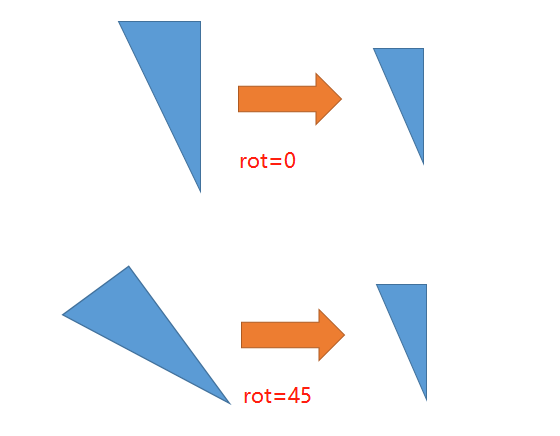
下面是SimplePose计算三个点的方法注释,它的巧妙之处在于用了方向向量。
# 根据center scale rot,将图像变换到 output_size对应的图像
# 最终目的是将center scale代表的box裁剪并缩放到output_size
# 这个函数的思路是在原图和目标图上,各构造一个对应的直角三角形(即:三个点)。
# 这两个三角形代表着仿射变换
# trans = get_affine_transform(c, s, r, self.image_size)
def get_affine_transform(
center, scale, rot, output_size,
shift=np.array([0, 0], dtype=np.float32), inv=0
):
if not isinstance(scale, np.ndarray) and not isinstance(scale, list):
print(scale)
scale = np.array([scale, scale])
# 外部计算scale时,以200作为分母,而不是图像的宽和高。比如box在原图的宽度是100,scale = 100/200 = 0.5
# scale_tmp = box的宽和高(在原图中的尺寸)
scale_tmp = scale * 200.0
src_w = scale_tmp[0]
dst_w = output_size[0]
dst_h = output_size[1]
rot_rad = np.pi * rot / 180
# 方向向量的作用是:为了产生除中心点外的,另外两个相对的点
src_dir = get_dir([0, src_w * -0.5], rot_rad) # 给定一个原图的点[0, src_w * -0.5],得到一个方向向量
dst_dir = np.array([0, dst_w * -0.5], np.float32) # 给定一个目标图的方向向量
# 创建两个3x2的矩阵
src = np.zeros((3, 2), dtype=np.float32)
dst = np.zeros((3, 2), dtype=np.float32)
src[0, :] = center + scale_tmp * shift # 这里shift==0,第一个点:原图center
src[1, :] = center + src_dir + scale_tmp * shift # 第二个点:center + 方向向量,得到一个相对于center的点
dst[0, :] = [dst_w * 0.5, dst_h * 0.5] # 目标第一个点:图的center
dst[1, :] = np.array([dst_w * 0.5, dst_h * 0.5]) + dst_dir # 目标第二个点:center + 方向向量,得到一个相对于center的点
# 第三个点计算方式: b + (a-b)[x=-y,y=x],与第一和第二个点组成直角三角形,第二点是直角点
# 这个点的计算比较灵活,与前两个点形成一个三角形的三个点即可
src[2:, :] = get_3rd_point(src[0, :], src[1, :])
dst[2:, :] = get_3rd_point(dst[0, :], dst[1, :])
if inv:
trans = cv2.getAffineTransform(np.float32(dst), np.float32(src))
else:
trans = cv2.getAffineTransform(np.float32(src), np.float32(dst))
return trans
小结:本函数执行affine transform的原理
给定对应的两个辅助向量,src_dir, dst_sir,代表着原图和目标图上,两个三角形的方向。 这个方向,体现在构造的三角形在原图中的方向与目标图中的方向成rot夹角。当rot==0,他们的方向相同,都指向 -y 轴.
- 第一个点:center
- 第二个点:center + src_dir
- 第三个点:与前两个点构成三角形的三个角点
trans =
[[ 5.62174032e-01 -0.00000000e+00 -1.56784364e+02]
[ 6.32078138e-17 5.62174032e-01 -1.24787177e+02]]
0.56 0 -156
0 0.56 -124
上述代码得到了一个变换矩阵,满足下图中变换策略。
![]()
上面提到第三个点是比较灵活的,比如,改成:
def get_3rd_point(a, b):
direct = a - b
# 故意乘了个n,向量方向没有改变,仍然构成三角形
# 得到的仿射变换矩阵不变
return b + np.array([-direct[1], direct[0]], dtype=np.float32) * n
可见,当rot=0时,得到的变换矩阵正好是平移和缩放矩阵;rot != 0 则多加旋转。
仿射变换不能解决周边是多余像素的问题,但我们可以是用box对原图先进行一次填充:
将box以外的像素填充为0。但当有多个box时,效率会比较低。此时,可以先将box变换到目标图像中,再进行一次填充。
对box进行变换:
# t与上面相同的变换矩阵获取方式相同,但,rot=0.
def affine_transform(pt, t):
new_pt = np.array([pt[0], pt[1], 1.]).T
new_pt = np.dot(t, new_pt)
return new_pt[:2]
Demo
在对应的yaml中修改TEST.MODEL_FILE,指向models/下面的model文件。
demo/demo.py 中修正drawbox函数。
python demo/demo.py --cfg experiments/coco/resnet/res50_256x192_d256x3_adam_lr1e-3.yaml --image test_data/000011.jpg --write
流程:
先使用Faster-RCNN检测人体,再使用仿射变换提取人体目标,送入SimplePose进行关键点检测。
完成后将关键点仿射变换到原图相对位置,画框,画关键点。
Demo改造
本节是为了快速接入工程,对Demo进行改造,做到 检测人体框 -> 截图 -> 获取关键点 -> 关键点处理,
既可以接收整图,也可以接收单独的人体目标图像,来获得关键点。
demo/demo.py添加 –images_dir 命令行参数,并使用glob.glob读取文件夹图像。
将从读取文件到保存图片的整个流程整理到一个函数中,如run_reference。
从video/image/images_dir获得文件路径都传入到run_reference。
总结
学习SimplePose(这里指Resnet/HRNet实现的Pose Estimation)是一个入门姿势估计的好方法,简单实用,网络实现不复杂,容易落地。
SimplePose中的仿射变换实现了等比例缩放的目的,将旋转、缩放、等比例、平移等一系列动作用变换来实现,是一种比较好的做法。