本文主要对ASL(Asymmetric Loss For Multi-Label Classification)进行了介绍,包括ASL的背景、思路、方法等,顺便对ASL的源码,对照论文进行分析和说明。
Abstract
positive/negative samples:正/负样本
Positive/Negative labels:正/负类标注
在多标签数据集中,一张图片往往包含有少量Positive Labels,和大量的Negative labels。这种称为类别间不平衡问题,是样本不平衡问题中的一种,也可以基本说是多标签分类中固有的问题。类别不平衡导致梯度不平衡,类别间的损失不平衡,最终表现是ACC较低。ASL 类似 Focal loss一样,达到了困难样本挖掘的目的,同时,还可以自动忽略掉错误标注的样本(错标样本)。
Introduction

上图表达的内容是:在一张图中,正样本只有少数,而负样本却非常多;ASL对这种不平衡,计算得到的loss有特殊含义,曲线的左边表示忽略了简单样本,而趋向于应对困难样本。
其实,正负样本不平衡不一定是上图描述的在单张图片中的表达方式,更体现在整个数据集中,label间的数量不平衡。
同时,不单单是多标签分类,目标检测任务中,前背景的样本不平衡问题也是相当的突出。
现有处理方案:
在Faster-RCNN中,只是用部分背景样本(subset)来计算loss,而对于多标签来说,提取的subset也是样本不平衡的;
Focal-Loss(更关注困难样本,但困难样本不一定包含足量的正样本;计算loss时,简单的背景样本也包含在内);
本论文提出一种非对称的loss,ASL(Asymmetric Loss)。它建立在两个关键点上:
- 将positive samples和negative samples解耦,并赋予它们独立的衰减因子(exponential decay factors);
- 通过平移negative samples的概率函数(称 probability shifting),来达到忽略简单negative samples的目的。平移的尺度是一个超参(所以称 hard thresholding)。
通过计算,经过probability shifting后的损失函数的导数,得出证明:probability shifting同时做到了忽略非常困难的样本(错标样本)的目的。
(错标被认为是在多标签标注任务中非常常见的问题。)
Asymmetric Loss
本小节,首先回顾 cross-entropy and focal loss,再介绍ASL,并给出其梯度公式和概率分析,最后提供了一个在训练过程中动态设置 loss’ asymmetry levels 的方法。
K:label 总数
Zk: label logit输出
σ(zk):logit经过激活函数sigmoid作为最终输出
Ltot:total loss

公式(1): CE loss
公式(2): BCE loss
公式(3): focal loss
ASL对CE loss的改装,将正样本损失和负样本损失进行解耦,就体现在将L拆分为 L+ 和 L−。
同时,focal loss也可以使用L+ 和 L−来表示。
其中, p = σ(z),当γ = 0,focal loss == BCE loss。
当 γ > 0 时,表示简单负样本的权重被降低(对越小的p,pγ 越小,L−越小,L越接近0),loss更倾向于关注困难样本(p比较大的样本)。
对于focal loss,有一个trade-off:当γ较大时,L+也被抑制了。为此,对focal loss解耦正负样本的衰减因子,得到公式(4):
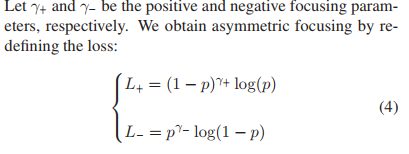
由于我们更关心正样本的贡献,所以,总是令:γ− > γ+。
(注意:ASL的分析,都省略了α,α用于表示正负样本数量的不平衡因子)
ASL的概率平移
在上述的focal loss中,γ的确可以抑制简单负样本,但是它做得不够彻底。ASL对其进行一个概率平移,以彻底忽略简单负样本。
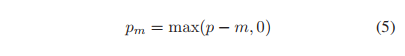
m ≥ 0,是一个超参。把公式(5)作用到L-上,得到:
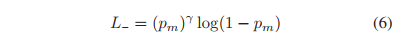
下面是设置 γ- = 2,m = 0.2 时的loss曲线:
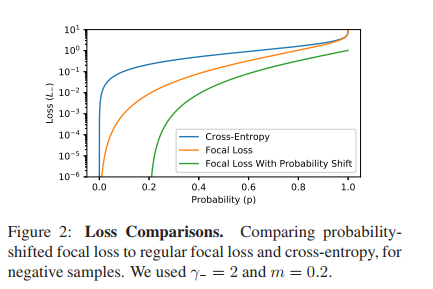
它表示,当p<m,即p<0.2时,L- == 0,由此可见,概率平移完全抑制了简单负样本。
m:论文中也称 asymmetric probability margin。
ASL Definition
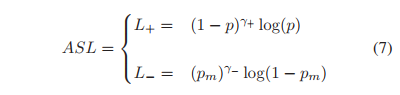
有了前面的描述,这个ASL公式,应当一目了然。
Gradient Analysis
L-对z求导,得到梯度:
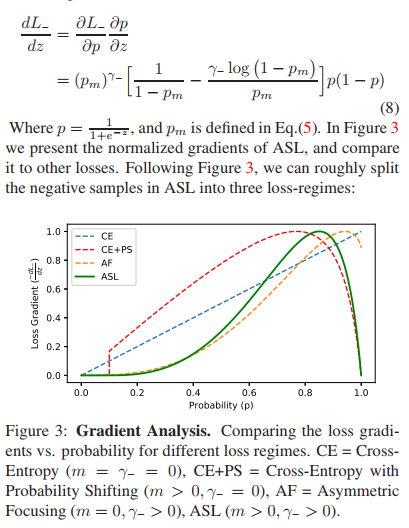
在上述ASL求导曲线的最高处,导数为零的地方,以此为界,右边部分,表示负样本的概率非常高,接近1.0。 这很可能说明,这个样本是错标样本。
为什么说对于负样本来说,概率高就是错标呢?
这里的概率是指:样本属于正样本的概率。所以,前面才会有,概率低于0.2(超参)是非常简单的负样本,同理,概率很高的负样本,很可能是正样本,只是被错标了。
Probability Analysis
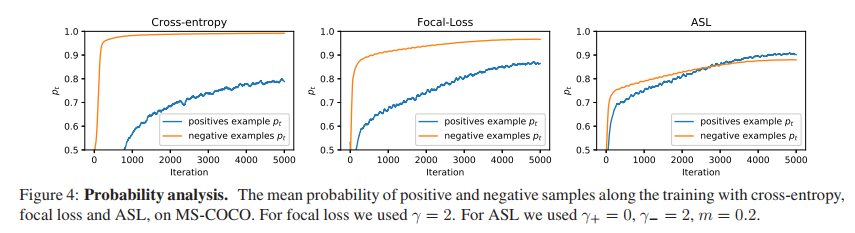
概率分析,讲得内容是网络在最后的正负样本的平均概率值,ASL的最后输出结果显示,正样本的平均概率基本等于负样本的平均概率,而CE Loss 和 Focal loss则不然。

Adaptive Asymmetry
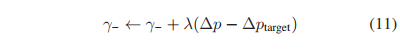
自适应的不平衡,L-中的衰减因子可以通过正负样本概率偏差来自动设置。
∆ptarget表示我们期望的概率偏差,∆p表示实际的概率偏差,由这两者来评估衰减因子γ-的取值。
∆ptarget:本人称它为正负样本的平均概率门限。
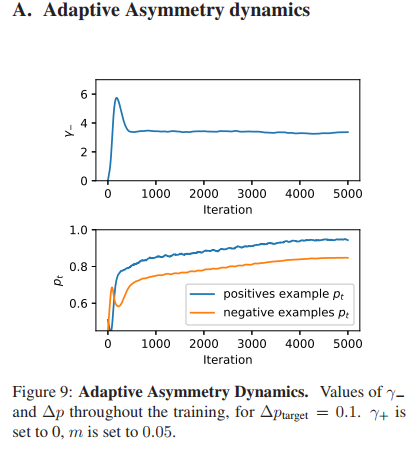
可以看到,训练任务进行到10%时,基本可以得到一个稳定的γ-。
Experimental Study
这里介绍了ASL各项试验,并从得出概率平移和正负样本平均概率门限的经验值。
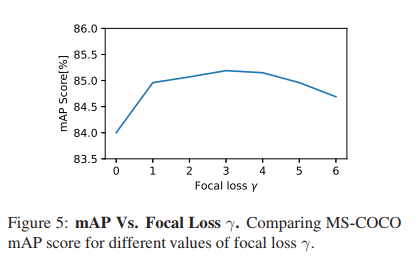
实验1:对于focal loss, γ 最佳取值2-4.
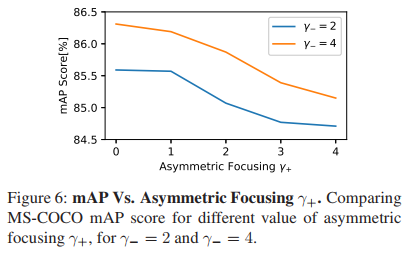
实验2:对于ASL,γ-给定时,γ+ 取 0 最合适
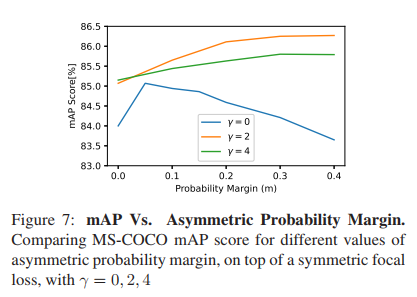
实验3:对于CE loss,m = 0.05,对于focal loss,0.3 ≤ m ≤ 0.4
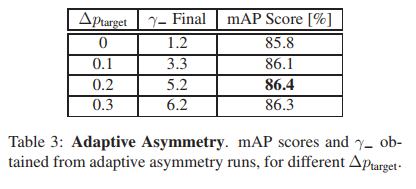
实验4:∆ptarget取0.2最佳
代码实现
待补充。。。
总结
ASL的设计可以说是使用了两个loss trick:
- 解耦正样本和负样本衰减因子
- 对概率进行平移来完全忽略简单负样本
额外还达到了一个效果:同时抑制了错标样本
ASL相比于focal loss,最终的评价指标普遍要提高0.几 ~ 几个百分点。
参考
Paper:https://arxiv.org/abs/2009.14119
Github:https://github.com/Alibaba-MIIL/ASL