- Abstract
- Introduction
- Method
- Data Augment
- Architectures for Encoder and Head
- Loss Functions and Batch Size
- SOTA对比结果
- 参考
本文介绍了无监督学习相关的A Simple Framework for Contrastive Learning of Visual Representations(SimCLS),以论文的原始形式排列。SimCLS使用对比学习(Contrastive Learning)来获得图像的视觉表示(Visual Representations),或者说是一种抽象特征。对于Resnet,representation是 average pooling layer 的输出向量。
Abstract
SimCLS属于一种自监督学习方法(self-supervised learning selfsupervised),我们主要展示了以下几个方面的发现:
- Data augmentations
- A learnable nonlinear transformation(在特征提取网络与对比损失之间建立一个非线性变换)
- SimCLS依赖于大的batch-size和更丰富的训练步骤
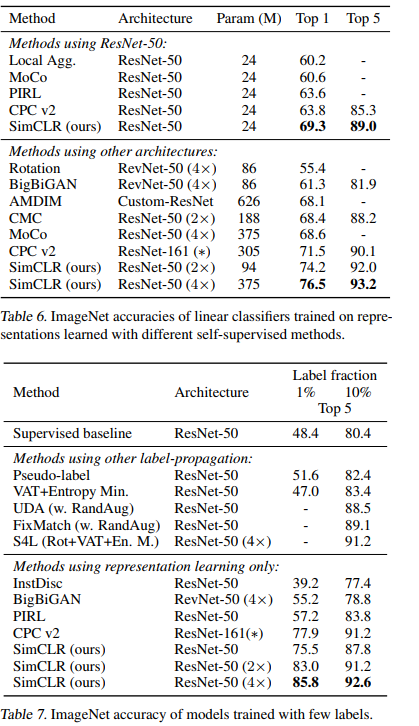
对SimCLS 学习到的representation进行一个简单的线性分类,就能在ImageNet上达到76.5% top-1 accuracy,且对1% labeled data 进行fine-tune,就能达到85.8% top-5 accuracy,胜过基于AlexNet的监督学习方法。
Introduction
SimCLR 实在是非常简单,主要由以下几个方面组成:
- 非常健壮的,经过实践验证的Data Augment
- 在representation and the contrastive loss之间建立一个非线性变换
- 损失函数采用contrastive cross entropy loss
- 更大的batch-size,更深-更宽的网络设计,更长的训练流程
Method
对比学习框架(The Contrastive Learning Framework),包含以下几个步骤:
- 将一个输入样本分别经过两个不同的data Augment策略,来产生两个新的样本(positive pair)。
- 然后经过一个使用神经网络实现的encoder,获得representations vector。encoder的选择是非常自由的,我们选择了Resnet。
- 在representation与loss之间接一个简单的2-layer MLP网络来实现非线性变换。
- 计算loss,正如下图,Zi 与 Zj的相似度最大化(Maximize agreement)。
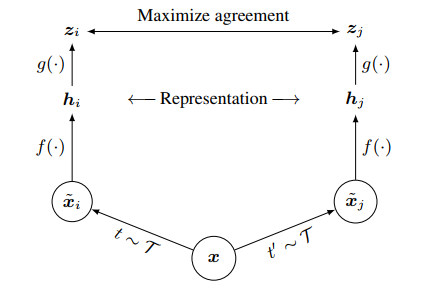

上图表面,loss是Zi 与 Zj的相似度最大化,τ 是一个为了平滑Softmax曲线的参数,它一定程度上能避免网络陷入局部最优解。h = representation = average pooling layer的输出向量。整个loss可以理解为:对positive pair 的 cos相似度,求其-log(softmax).

上图给出了SimCLS的训练策略,在选出的一个batch的N个样本中,分别进行两次data augment,得到两个不同的样本,一个用奇数,另一个用偶数表示,共有2N个。计算每一个样本i,与另一个对应的样本j的相似度Si,j.最后的loss,是2N个样本相互相似度损失的平局值L。L最小时,就是Si,j最大,表示经过data augment后的两个样本,representation没有改变。
Data Augment
SimCLS采用了这样的data augment:randomly crop -> resize to origin size -> color random color distortions -> random Gaussian blur.

为了验证各种data augment对SimCLS的作用,使用ACC来衡量增强方法的有效性,最终得出上表。表明,随机裁剪和颜色失真(random cropping and random color distortion)的先后组合方式是最有效的增强方法。同时,监督学习中的数据增强方法,如AutoAugment不一定适合SimCLS。
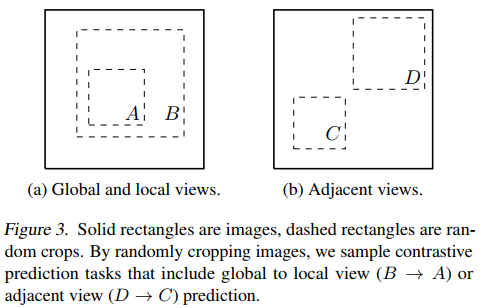
使用上面两种crop技巧,胜过很多以往的复杂的数据增强结构设计。
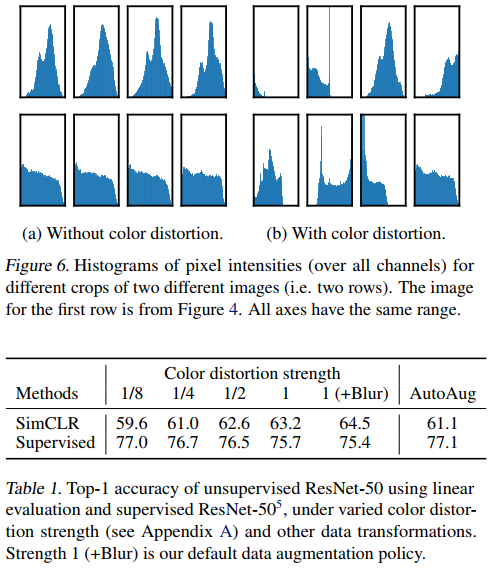
颜色失真是一个非常重要和健壮的增强方法,上图表面,仅仅通过颜色直方图就区分实例图像与其它图像,进行颜色失真增强后,不具有可分性。同时,颜色失真对SimCLS性能提升明显,Strength 1 (+Blur) 的增强方式效果最好。
同时,这里也提到了一个增强的思路:对于哪些不希望模型学习,用来划分数据的特征,应当通过增强来混淆它们,从而避免模型去学习。
Architectures for Encoder and Head
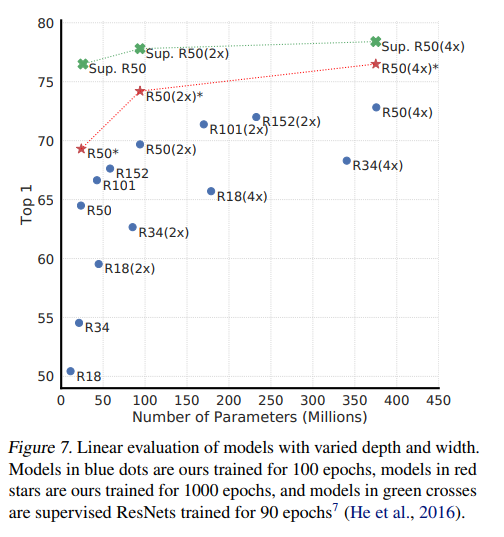
无监督学习需要一个大模型, increasing depth and width both improve performance。
在representation和计算loss之间,增加一个非线性变换,比恒等映射和线性变换效果要好。所谓非线性变换,就是加入hidden layer and RELU activation。
加入非线性变换,可以对representation进行一次过滤,去除不需要的信息,h 得到了提炼(提炼?怎么突然有种炼丹的feel),使得它更适用于后续/下游任务(downstream task)。
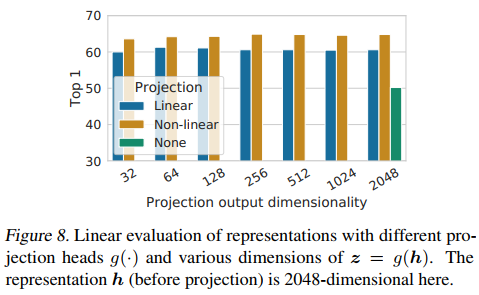 使用非线性变换时,映射的输出 z=g(h) 等于 2048维时,效果最好。
使用非线性变换时,映射的输出 z=g(h) 等于 2048维时,效果最好。
Loss Functions and Batch Size

上图给出了三种不同的负梯度函数公式及其对u的求导公式,NT表示 Normalized Temperature-scaled。
对于NT-Xent,没有什么特别的,其实是对前面提到的SimCLS loss,positive pair的l(i,j)的log展开。与其它两种loss对比,NT-Xent的效果最好。
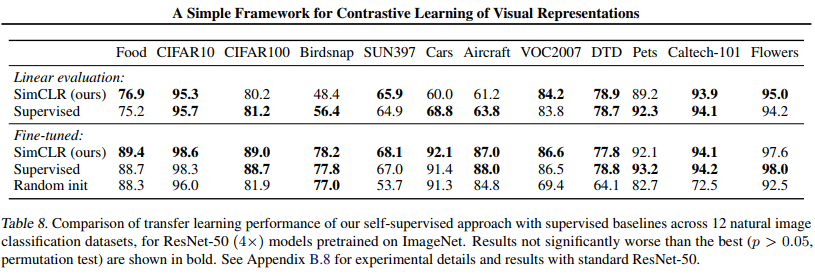
SOTA对比结果
贴一下结果,完毕。