SimCLSv2是对SimCLS的改进,之所以有本文,是因为SimCLSv2文章中的描述更能体现当前半监督学习的一般形式,明确描述了半监督学习的落地策略,如何从大模型指导小模型,提升实际场景的效果。SimCLSv2全称:Big Self-Supervised Models are Strong Semi-Supervised Learners,就是更大更强的自监督学习模型,更优的半监督学习器。
介绍
对于few labeled dataset,一种典型的做法是在大量标签的样本中学习一个大模型(big-model),这个过程称为unsupervised pretraining,紧跟着使用监督学习方法进行fine-tuning。预训练时使用无标签数据集,称为task-agnostic way,在ImageNet上,优于半监督学习方法。SimCLSv2的关键是使用了大模型,并且,无标签数据越多,大模型的效果越好,经过fine-tunning之后(带标签),大模型可以进一步在无标签的样本上进行知识蒸馏,得到小模型(这称为task-specific way)。
SimCLS半监督学习可以概括为三步:使用SimCLRv2在大量无标签样本上训练大模型,在少量的带标签样本上进行fine-tuning,然后使用无标签样本在特定场景上进行知识蒸馏。可以用一幅图来表示这个过程:
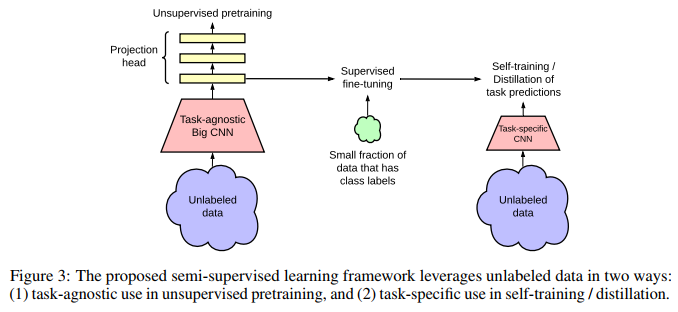
SimCLSv2主要的发现和贡献可以概括为:
- task-agnostic阶段应该使用更大的模型和无标签样本,作为测试,下图给出了该阶段使用带标签样本的比例与其效果的关系曲线
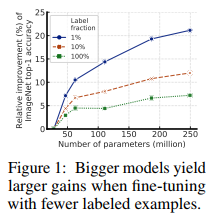
然后使用少量标签样本进行fine-tuning,即使样本过少会存在过拟合的风险,这样做的效果依然很棒。 - 大模型学习到了通用的特征表示(general visual representation)可以直接应用到特定的场景下(specific target task),而无需额外的其它representation。也就是说,大模型的表示能力已经足够强,以至于,在特定场景下时,可以直接使用无标签样本进行学习,获得小模型。
- 进一步证明了representation与loss之间的非线性变换的重要性,类似在SimCLS中提到的一样。做法:deeper,2-layer -> 3-layer. fine-tuning 使用1st-layer。
达到了SOTA的效果:
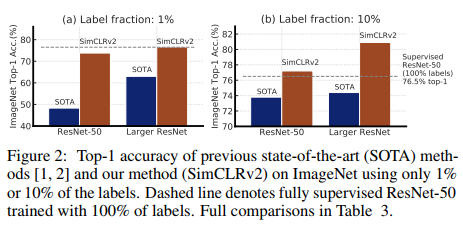
上图中的 label fraction 表示的是,在 fine-tuning 中,标签样本的占比。
Method
task-angostic:对 unlabeled data 进行无监督学习,得到big-model
fine-tuning:对 labeled data 进行fine-tuning,得到fine-tuning big-model
task-special:
1. 使用 fine-tuning big-model 获得 unlabeled data with imputed labels(标签估计)
2. 使用 imputed labels 训练 small-model(知识蒸馏的方式)
SimCLSv2 vs SimCLS
在SimCLS中,将输入样本经过两个 data augment 后,学习两个 representation,并使用一个2-layer MLP进行可学习的非线性变换,得到Zi和Zj。

SimCLSv2做了三方面的改进:
- 网络更deeper,加入了channel-wise attention mechanism(selective kernels,SK),称为ResNet-152 (3×+SK);而SimCLS 用的是Resnet-50(4x)。这个改变很重要,见 Figure-2 中,基于1% labeled data fine-tuning时,居然后29%的提升。
- MLP 从 2-layer 加到 3-layer,与SimCLS在fine-tuning时完全去掉 MLP 不同的是,SimCLSv2 从1st-layer 进行fine-tuning,因此获得14%的提升效果。
- 使用了一个类似MoCo中提到的memory network,获得~1%的提升。
Knowledge distillation
将fine-tuning得到的网络作为teacher network,直接使用 unlabeled data 来蒸馏 student network。tearcher network 给 student network 提供伪标签样本。distillation loss 是一个被去除真实标签的loss:

Others
剩下的内容是一下经验、大模型越大越好、MLP越深越好、基于无标签样本的知识蒸馏(蒸馏和自蒸馏)等等。略