YOLOv5的网络结构展示,结合分析代码实现,使用Netron进行可视化。
YOLOv5网络结构图
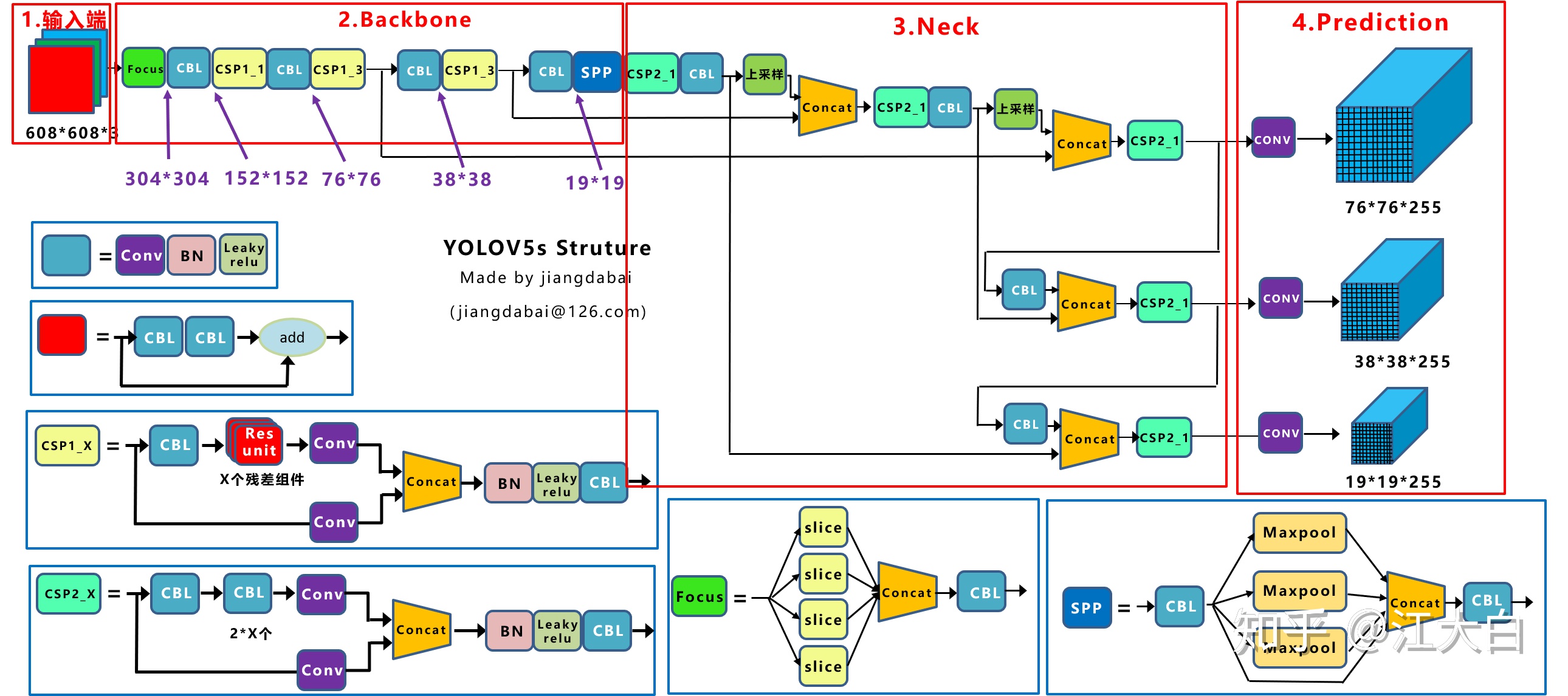
看大图去https://zhuanlan.zhihu.com/p/172121380,或者另存为。
ONNX
可视化部分是先将pt导出为ONNX模型,再通过netron查看。其中,Conv和BN被融合在一起,这是因为BN在推理时无需更新参数,且推理过程满足Conv的计算公式,能合二为一。
好处是加快了推理,在量化任务中,也提高了精度(在高精度先乘,相比转换为低精度再乘,减小了精度损失)。
详情见参考文档
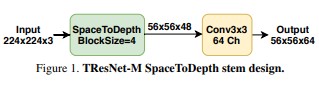
Focus
Focus 模块来源于 TResnet 中的 SpaceToDepth。要知道,传统的缩减尺寸的方法是采用大的kernel,比如Resnet50,7x7的kernel size,而更精细的kernel size应该是3x3。为了降低大卷积核的弊端,SpaceToDepth达到了快速缩减尺寸,同时保留信息的目的。
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
# self.contract = Contract(gain=2)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
# return self.conv(self.contract(x))
接Conv的目的是使得输出通道是确定可知的。
切片举例,x[…, 1::2, ::2],对最后两维进行间隔为2的索引,倒数第二维从1开始,最后一维从0开始。
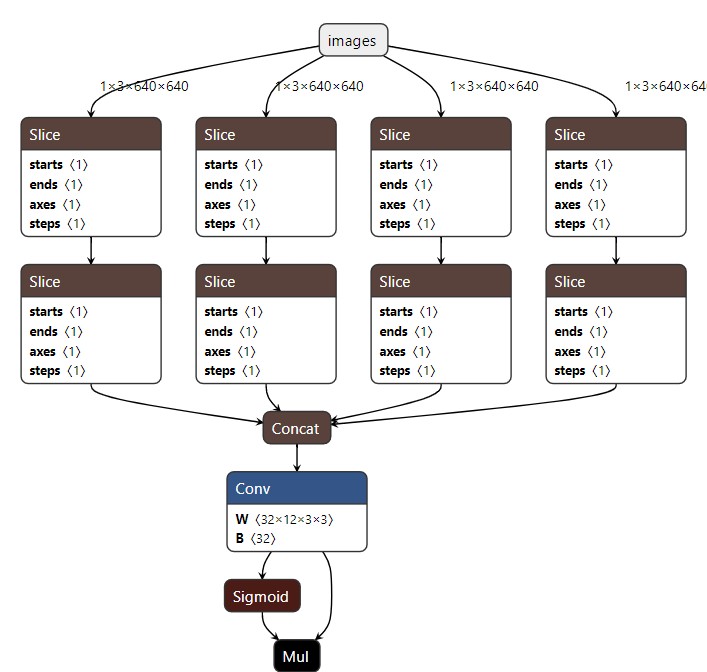
ONNX使用了两个连续的Slice完成切分,每一个Slice完成一个维度的切分,共两个维度。
CBL
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act is True else (act if isinstance(act, nn.Module) else nn.Identity())
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
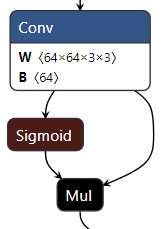
CBL: Conv2d + BatchNorm2d + activation,L原来表示LeakyReLU。在代码中,它等于一个Conv
fuse:将Conv2d 和 BatchNorm2d融合为一层,此时bn可以是去掉或者是nn.Identity()
nn.Identity(): output = input
activation:默认是SiLU,也可以是给定的继承nn.Module的其它激活函数,比如ReLU或者自定义的,甚至是不需要激活函数
SiLU:ONNX没有直接实现,仍然转换为 sigmoid + Mul,Mul是两个输入的按位乘
Res unit
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
Resnet单元,但也不完全相同,原始的Resnet unit有三个Conv2d,且是先相加,后接激活函数。这里是两个Conv2d,且是先激活,后与输入相加。原始Resnet-Bottleneck的实现:
def forward(self, x: Tensor) -> Tensor:
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
conv1/2/3:Conv2d
本人并不清楚这么做的原因,浏览网络上别人实现的CSResnet的做法中,renset block 是先加后激活。比如: https://github.com/horuakut1/CspDarkNet53_pytoch/blob/main/CspDarkNet-53.py
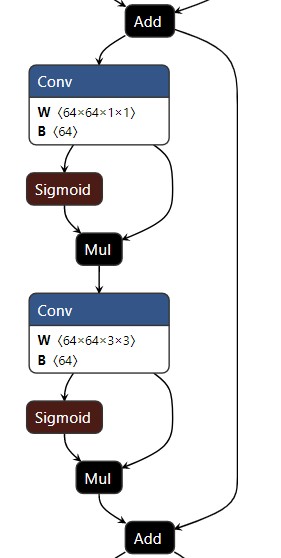
ONNX可视化也很明确,两个Conv,input直接加到output上。
值得注意的是,Res unit只在CSP中使用。
CSP
yolov5中的CSP模块,设计来源自CSPNet的思路。
参考文档中给出了两个CSP,包括CSP1_X和CPS2_X,并表示一个在backbone中使用,另一个在neck/predict中使用。在yolov5代码中,只有一个,C3。shortcut=True表示CSP1_X,shortcut=False表示CSP2_X。
参考文档的CSP内的Conv模块同样存在先相加还是先激活的差异。
class C3(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # act=FReLU(c2)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
# self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
C3:CSP Bottleneck with 3 convolutions,包括三个Conv的CSP模块。
Bootleneck:可以有n个。
CSP模块总结起来就是:
- 将输入拆分为两个部分,通道数均等于输出通道的一半(后面会cat起来),x1和x2
- x1经过Res unit(n个)
- output = Conv(x1 + x2)
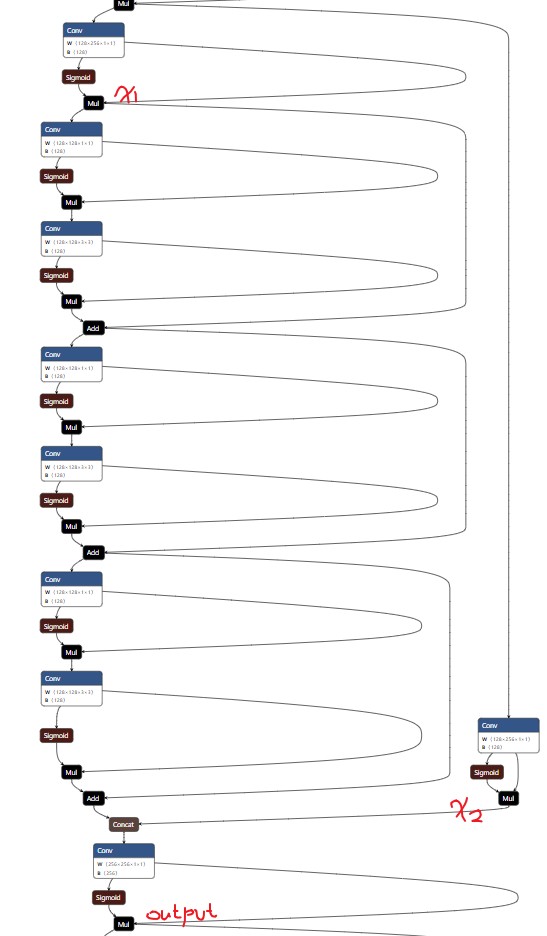
注意红色字体,正式上面总结的x1,x2和output,Res unit有3个。
当shortcut=False时,ONNX可视化如下:
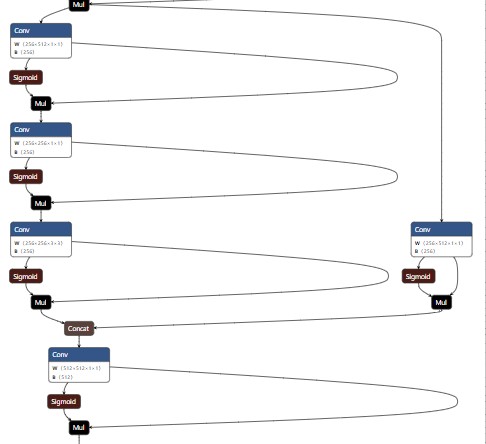
过了SPP之后,后面的CSP模块,全部都是CSP2_x:
在yaml中,CSP2_X配置为:[-1, 3, C3, [1024, False]],第二个参数是False。
SPP
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
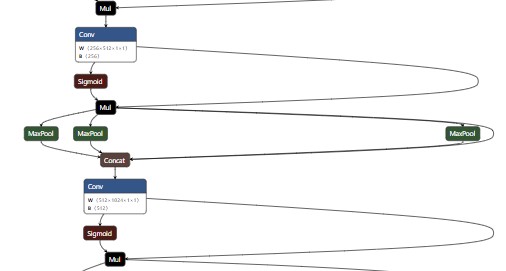
MaxPool2d采用不同的kernel,分别对经过Conv的x进行池化操作,得到 len(k) 份feature map,并且,feature map的尺寸与它本身的输入尺寸相同。
cv2的输入通道数正好是被放大了len(k)+1倍,= c_ * (len(k) + 1)
1x1卷积与下采样
整个网络的结构非常清晰,凡是网络中的组成模块,除了独立的CBL,都是以1x1卷积对输入x进行处理。在backbone中,独立的CBL负责下采样,且全部是3x3的卷积核,每次缩放1/2.
1x1卷积的好处:减少参数,降低计算量,加强通道间信息交换,因此,网络可以做得更深更灵活。
比如前面CSP的第一个Conv,就是1x1卷积核,实现了可学习的通道拆分。
再加上Focus、CSPNet的使用,整个网络可以做得非常小,速度非常快。
Neck与特征金字塔
YOLOv5通过上下采样通过两个方向(FPN + PAN)融合了特征信息,盗图:
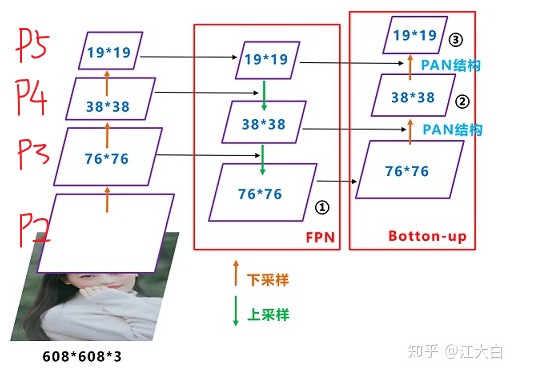
序号1、2、3正是最终的三个输出节点。
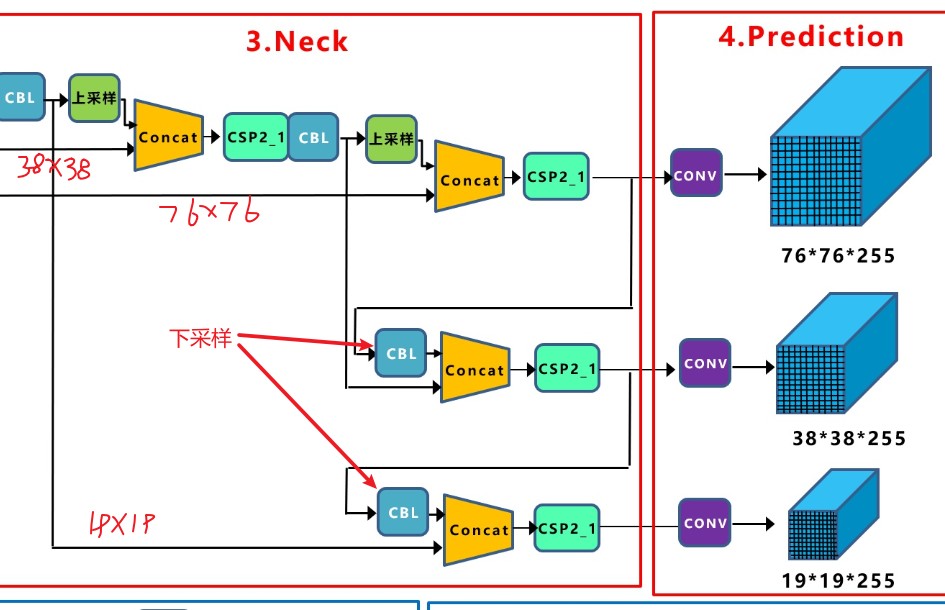
上图对应到顶端的网络结构图:
yaml及其配置
以YOLOv5s.yaml为例.
所有的解析任务都落在函数:def parse_model(d, ch): # model_dict, input_channels(3)
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
对应于[from, number, module, args]
n = max(round(n * gd), 1) if n > 1 else n # depth gain,直接乘系数,不小于1
c2 = make_divisible(c2 * gw, 8) # width gain,8的倍数
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
网络的深度:层数,越多,越深
网络的宽度:通道数,越多,越宽
具体见本小节的代码注释。
depth_multiple:深度配置乘以该系数
width_multiple:宽度配置乘以该系数
5-P4/16:表示第5层,FPN中的P4,缩放16倍。缩放的倍数是输入image的尺寸与当前feature map的倍数关系,可以是2、4、8、16、32。
backbone中的这种信息就表明,Focus层缩放2倍,接着每一个Conv缩放2倍。
backbone和head中的配置,每一项表示:
[from, number, module, args]
并且,除了C3以外,其它的number都是1,对于C3,number表示内含CBL 或者 是Res unit的个数,等于前面CPS1_X和CSP2_X中的X。
当from是一个list时,比如[-1, 4],表示当前层要与第4层进行融合,融合的方法取决于module的类型,只有Concat和Detect会融合多层信息。
总结
YOLOv5的网络结构非常简单,使用了很多trick,SpaceToDepth、CSPNet、FPN/PAN都是很棒的技巧。
代码中还出现了C3TR,想必不久之后就有支持vision transformer的版本出来。
参考
https://zhuanlan.zhihu.com/p/172121380
https://github.com/ultralytics/yolov5
https://github.com/onnx/onnx/blob/master/docs/Operators.md
https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
TResnet Paper
融合Conv和BN,加速推理