本文给出了一个分析图像的主题颜色,或者说是主要颜色的方法和实现。它可以提取一幅图像中,比如服装,的主要颜色。
1. 现有方法
- 对目标区域计算颜色均值;
- 使用神经网络直接进行颜色分类,类别设定为主要的几种颜色;
- 提取一定范围内的HSV值,统计这些值的总数,以最多的值作为主要颜色;
- 将颜色视为回归问题,使用神经网络进行颜色值识别。
颜色回归:
下面讲讲我的做法,实验效果非常不错。
首先,为图像标定一种主色,得出一个RGB标签;再者,定制神经网络,输出RGB值;最后,loss函数是RGB的方差。详情略。
它最重要的缺点是:标注成本太高。
2. 新思路介绍
仍然是把颜色分析当做回归问题,假定颜色的渐变是一个线性的过程,不同的光照,环境色温的影响,导致的变化是线性的。
问题的目标变成:获得某段颜色(一个范围)的像素分布,该颜色范围内,像素密度比周围的密度都大,统计该范围内像素的个数,像素最多的某段颜色为主要颜色。
而这正是密度聚类该做的事。 由于是识别,具体的颜色类别数量是无法确定的,MeanShift正好满足需求,不像K-means一样需要指定一个类别总数K。
颜色模型中,可以使用RGB、HSV两种模型进行聚类。RGB的颜色线性关系中,分段性不明显,MeanShift带宽参数不好确定。
HSV分段较明显,MeanShift带宽可以根据H通道进行设定,缺点是,由于SV范围比较宽,同一个带宽参数无法适应H和SV。所有,又有了H通道模型,单独对H通道进行密度聚类。
3. sklearn Meanshift 接口说明
ms = MeanShift(bandwidth=bandwidth).fit(x)
labels=ms.labels_
cluster_centers = ms.cluster_centers_
x:输入,必须是2D,第一维是数据index,第二维是元素(要进行聚类的点),每一个元素的维数是任意的;
bandwidth: 带宽;
labels_:聚类的类别结果,保存了每一个元素所属的类别;
cluster_centers_:聚类的结果,表示中心点,表征了具体的类别;
比如 x 是一系列的RGB值,元素是3D数据,x是2D数据。labels_表示每一个像素点的类别id,cluster_centers_表示最终的分类结果。
4. 代码实现
img_file = "8_out.jpg"
img_raw = cv2.imread(img_file)[:,:,::-1]# BGR 2 RGB
def color_mean_shift(rgb,
use_hsv = True,
only_h = True,
bandwidth = 10,
show_center = True,
show_disptrubition = True):
img = cv2.resize(rgb, (50,25))
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY).reshape(-1,1)
if use_hsv:
hsv = cv2.cvtColor(img, cv2.COLOR_RGB2HSV)
hsv_flatten = hsv.reshape(-1,3)
img_flatten = img.reshape(-1,3)
not_black_index = np.where(img_gray > 10)[0]
img_not_black = img_flatten[not_black_index]
if use_hsv:
hsv_not_black = hsv_flatten[not_black_index]
img_flatten.shape, img_not_black.shape
if use_hsv:
x = hsv_not_black
if only_h:
x = hsv_not_black[:,0:1]
else:
x = img_not_black
ms = MeanShift(bandwidth=bandwidth).fit(x)
labels=ms.labels_
cluster_centers = ms.cluster_centers_
fig=plt.figure(figsize=(10, 10))
if show_center:
ax=fig.add_subplot(121,projection ='3d')
if not use_hsv:
ax.set_xlabel("R")
ax.set_ylabel("G")
ax.set_zlabel("B")
else:
ax.set_xlabel("H")
ax.set_ylabel("S")
ax.set_zlabel("V")
count = np.bincount(labels)
sort_count = list(reversed(np.argsort(count)[-9:]))
if use_hsv:
if only_h:
sv = np.zeros((cluster_centers.shape[0], 2))
sv[:] = (220,220)
cluster_centers.shape,sv.shape
cluster_centers = np.concatenate((cluster_centers, sv), axis=1)
center_rgb = cluster_centers[None,:,:].astype(np.uint8)
cluster_centers_rgb = cv2.cvtColor(center_rgb, cv2.COLOR_HSV2RGB).reshape(-1,3)
else:
cluster_centers_rgb = cluster_centers
point = tuple(cluster_centers_rgb/255)
ax.scatter(cluster_centers[:,0],cluster_centers[:,1],cluster_centers[:,2],
marker=".",s=50,c=point,linewidths=5,zorder=10, alpha=0.6)
cluster_centers = cluster_centers[sort_count]
for count_index, max_center in enumerate(cluster_centers):
txt = '$' + str(count_index+1) + '$'
ax.scatter(max_center[0],max_center[1],max_center[2],c='b',s=150,marker=txt)
if show_disptrubition:
axd=fig.add_subplot(122,projection ='3d')
if not use_hsv:
axd.set_xlabel("R")
axd.set_ylabel("G")
axd.set_zlabel("B")
else:
axd.set_xlabel("H")
axd.set_ylabel("S")
axd.set_zlabel("V")
point = tuple(img_not_black/255)
if use_hsv and only_h:
x = hsv_not_black
axd.scatter(x[:,0],x[:,1],x[:,2],
marker=".",s=2,c=point,linewidths=5,zorder=10, alpha=0.6)
plt.show()
color_mean_shift(img_raw, use_hsv=False, bandwidth=20)
color_mean_shift(img_raw, use_hsv=True, only_h=True, bandwidth=5)
color_mean_shift(img_raw, use_hsv=True, only_h=False, bandwidth=20)
代码结构:
- 读取一张图像,转换为RGB和HSV格式,以及对应的GRAY格式;
- 通过GRAY格式,排除掉不期望统计的颜色值,比如纯黑色(图像是分割结果,纯黑色是背景,详情见后文);
- 提取需要统计的颜色值,reshape为2D数组,每一个元素是需要进行聚类的样本点;
- 样本点分为:RGB、HSV、独立的H通道,共3种情况;
- 对比三种情况的聚类结果。
5. 聚类结果展示

上面是一副经过GrabCut抠图的图像,背景是纯黑色。
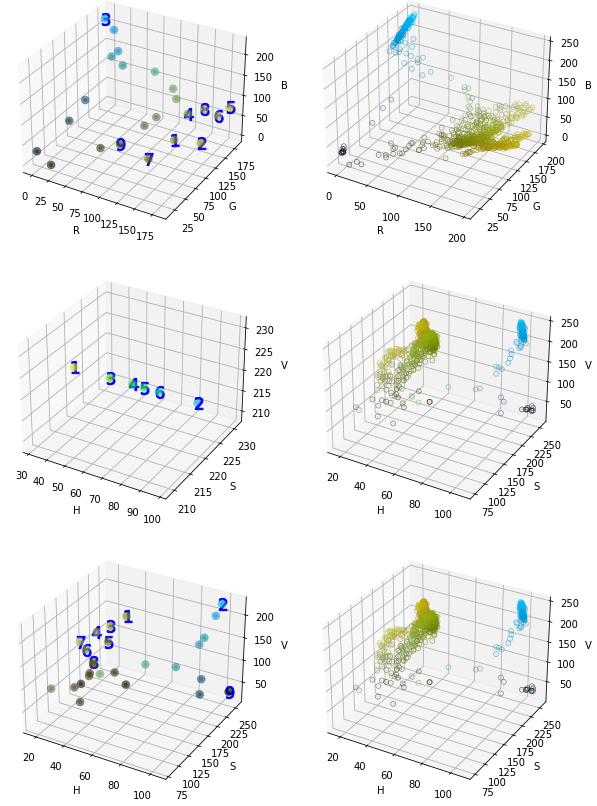
结果说明:
聚类结果图中,圆形的点是类别的中心点,圆形的颜色是聚类中心点的颜色值,数字1-9表示该中心点所属类别的像素个数排序。
从结果图中可以看到,黄色的元素(像素)数量最多。
- 顶部两张结果图,是RGB模型的聚类结果。
- 中间是独立H通道的聚类结果。
- 最后两张是HSV模型的聚类结果。
从上面3张图可以看出,虽然3个聚类结果都能识别主要颜色是黄色,但是,只有独立H通道能识别出次要颜色是蓝色。
当背景不是纯黑色的时候,我们看看结果。

上图没有经过抠图,背景中除了黑色,还有较暗的红棕色。
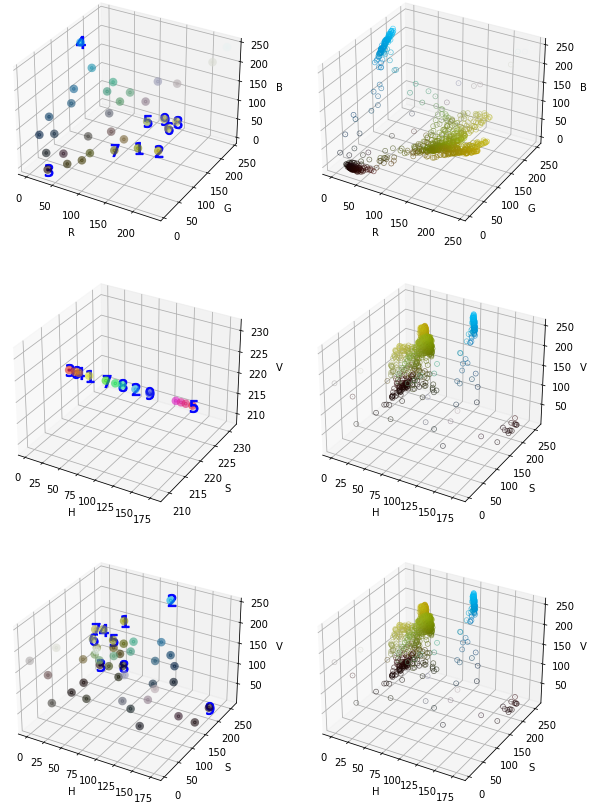
可见,无论是RGB还是HSV模型,都可能受到颜色复杂度的影响,颜色越复杂,识别结果越奇怪,这是因为,纯色较多的区域,聚类结果中,对应的像素数量会急剧上升。而哪些渐变色,我们人眼认为相同的颜色,在RGB/HSV模型中,它们相距甚远,无法聚类到一起。
使用HSV模型,则要求均匀的光照,这样V通道对聚类的影响明显减小。但是,S通道仍然由于范围太广而得不到较好的聚类结果。
所以,推荐使用独立H通道模型,附加RGB模型应对黑、白、灰三种颜色。
6. 服装颜色聚类
在项目上,我们可以使用服装分割模型对人体目标进行分割,提取服装区域。然后使用聚类,获得类别,从而达到识别服装颜色的目的。
为了简单,这里使用GrabCut进行分割,提取服装区域。

上面是一套红色的服装,看看聚类的结果表现。
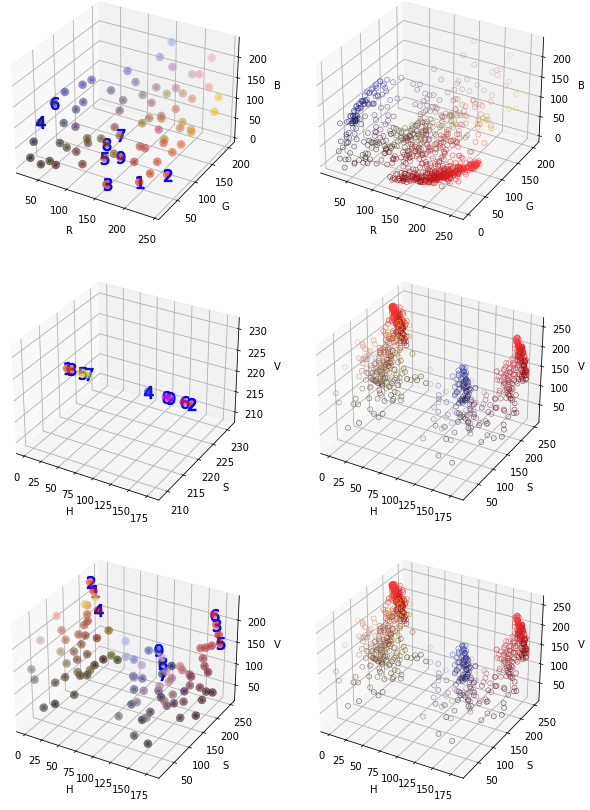
三种建模方式,都能正确识别为红色服装。
7. 特殊情况说明
使用RGB、HSV可以明确聚类出所有的颜色值,但是单纯使用H通道则不行。在HSV颜色模型中,黑色、白色、灰色的H通道都是非常宽的。
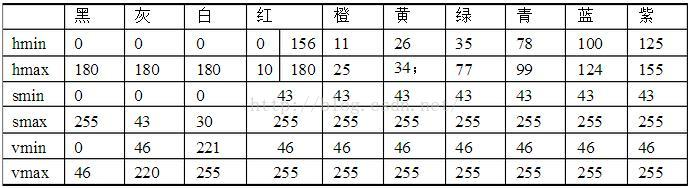
黑、白、灰,只能通过SV通道进行分类,不能使用H通道。
当单独使用H通道时,必须先判断黑、白、灰。简单的做法是,先进行RGB聚类,如果分类落在它们之间,判定颜色为其中之一。否则,再使用H通道进行聚类。
8. 代码
9. 参考
sklearn-MeanShift
OpenCV-GrabCut