- 编码表
- 一个简单的例子
- Base 128 Varints
- Message Structure
- More Integer Types
- Length-Delimited Records
- Optional and Repeated Elements
- Maps
- Field Order
- 参考
本文介绍了protobuf的编码原理,描述了如何从protobuf数据变成具体的二进制编码,生成的二进制数据可以传输到网络或者存储到文件中。通过了解编码的具体规则,可以理解protobuf的压缩机制,理解其优势的由来,还可以对我们优化RPC程序带来帮助。
编码表
message := (tag value)*
tag := (field << 3) bit-or wire_type;
encoded as varint
value := varint for wire_type == VARINT,
i32 for wire_type == I32,
i64 for wire_type == I64,
len-prefix for wire_type == LEN,
<empty> for wire_type == SGROUP or EGROUP
varint := int32 | int64 | uint32 | uint64 | bool | enum | sint32 | sint64;
encoded as varints (sintN are ZigZag-encoded first)
i32 := sfixed32 | fixed32 | float;
encoded as 4-byte little-endian;
memcpy of the equivalent C types (u?int32_t, float)
i64 := sfixed64 | fixed64 | double;
encoded as 8-byte little-endian;
memcpy of the equivalent C types (u?int32_t, float)
len-prefix := size (message | string | bytes | packed);
size encoded as varint
string := valid UTF-8 string (e.g. ASCII);
max 2GB of bytes
bytes := any sequence of 8-bit bytes;
max 2GB of bytes
packed := varint* | i32* | i64*,
consecutive values of the type specified in `.proto`
注释
message := (tag value)*
A message is encoded as a sequence of zero or more pairs of tags and values.
//message被编码为0个或者多个tag-value数据对。
tag := (field << 3) bit-or wire_type
A tag is a combination of a wire_type, stored in the least significant three bits, and the field number that is defined in the .proto file.
//tab被编码为fied_number + wire_type,其中,低3位用来描述wire_type,其它的高位用来表示field_number。field_number具体需要占用几个二进制位,是根据number的大小决定的。如果比较小,则,tag只需要一个字节,否则需要多个字节来表示。
value := varint for wire_type == VARINT, ...
A value is stored differently depending on the wire_type specified in the tag.
//value的长度是是取决于wire_type和具体的数据长度。对于可变整形,使用VARINT表示。对于需要注明后续数据长度的数据,比如字符串,则使用TLV的形式表示。TLV = tag length value,tag就是前面提到的tag,length则表示了v的具体占用字节数。所以,在TLV形式的数据中,这里value==LV。
varint := int32 | int64 | uint32 | uint64 | bool | enum | sint32 | sint64
You can use varint to store any of the listed data types.
//可变整型数可以表示的数据类型包括32、64位有无符号整形,bool和enum都是可以表示的。
i32 := sfixed32 | fixed32 | float
You can use fixed32 to store any of the listed data types.
//也许为了考虑到精度问题,i32表示直接是32个二进制位表示数据。也就表示这,这类数据不会被压缩。
i64 := sfixed64 | fixed64 | double
You can use fixed64 to store any of the listed data types.
//与i32同理。
len-prefix := size (message | string | bytes | packed)
A length-prefixed value is stored as a length (encoded as a varint), and then one of the listed data types.
//长度前缀,在表示message、string、bytes、packed时都需要指定数据的长度。
string := valid UTF-8 string (e.g. ASCII)
As described, a string must use UTF-8 character encoding. A string cannot exceed 2GB.
//string默认采用UTF-8表示,且,长度不能超过2GB。
bytes := any sequence of 8-bit bytes
As described, bytes can store custom data types, up to 2GB in size.
//与string相同。
packed := varint* | i32* | i64*
Use the packed data type when you are storing consecutive values of the type described in the protocol definition. The tag is dropped for values after the first, which amortizes the costs of tags to one per field, rather than per element.
//表示将数据打包,对于连续相同类型的数据内容,除了第一个数据指定数据格式外,后续的数据沿用第一个数据的数据格式,从而可以节省空间,打包格式在proto3中是默认的。
一个简单的例子
message Test1 {
optional int32 a = 1;
}
假设我们将a赋值150.最终,这个message会被编码为 08 96 01。如果使用proto text format表示的话,可以表示为1:150。
Base 128 Varints
这是一种most significant bit (MSB) 编码方式,翻译为“最高有效位”,如果一个字节的最高有效位是1,表示它后面还有一个字节,否则表示最后一个字节。
比如0000 0001表示数字1,而10010110 00000001表示两个字节,hex编码对应96 01。那么,这里的两个字节对应的整数是多少呢?
10010110 00000001 // Original inputs.
0010110 0000001 // Drop continuation bits.
0000001 0010110 // Put into little-endian order.
10010110 // Concatenate.
128 + 16 + 4 + 2 = 150 // Interpret as integer.
反编码步骤:
- 首先需要去除msb的连续标志位
- 然后转换为小端模式
- 然后将它们连接起来,变成标准的8位二进制数
- 将得到的二进制数直接转换为整型数
Message Structure
Message的结构,在编码中已经有所表示,这里做更加详细的说明。还是以上面的08 96 01为例,前面的08表示了message的结构信息。将08展开,得到0000 1000。由于最高位是连续标志位,为0表示后面没有字节了。所以,000 1000表示了这个message字段的结构。后三位000表示VARINT,其余位000 1等于1,表示message中的第一个字段。由于该字段的值类型是VARINT,后续读取数据时,按照VARINT的格式进行解析。

More Integer Types
Bools and Enums
使用int32表示,特殊的bool只会被编码为00和01。
Signed Integers
从前面的内容看,VARINT好像只能表示非0数,对于负数如何处理?
ZigZag编码:对于一个非负整数n,使用2、*n表示,对于一个负整数n,使用2*n+1表示。如是:
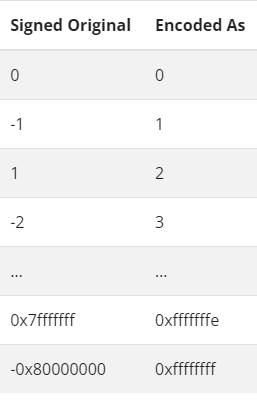
在计算机中,可以这样完成快速编码:
((n + n) ^ -(n < 0)) - (n < 0)
Non-varint Numbers
对于这类型数据,比如double和fixed64,直接使用8个byte来表示,float和fixed32则使用4个byte来表示。
Length-Delimited Records
对于一些需要通过数据长度来指定的数据类型,比如string,需要使用TLV的格式。所以在形如tag-value的message内容中,value前面带上了一个LEN前缀,以表示这个value的长度。
举例:12 07 [74 65 73 74 69 6e 67]
上述前两个数据中,tag=12(hex),转换为二进制,0001 0010,去除连续标志0,再写作tag的二进制格式,0010 010。查看“Message Structure”一小节,可以得到010==2,表示该字段的数据类型是LEN。所以,写成protobuf的text格式,2:LEN。
所以,接下来的数字07==7,表示后面的数据长度是7个byte。那LEN可以表示string, bytes, embedded messages, packed repeated fields中的任意一种。么,这7个byte的数据具体表示什么呢?
这就跟解析端的.proto文件指定的数据类型决定了,如果是指定为string,则解析为字符串testing,如果指定为bytes则不用进行二次解析,仅仅代表7个字节而已。
Submessages
即上面提到的LEN可以表示为embedded messages,这种机制支持嵌套的message。那么,7后面的数字将以一个全新的自定义数据类型进行解析。
message Test3 {
optional Test1 c = 3;
}
比如上述中第一个字段的数据类型是Test1,则,LEN后面的数字将会被按照一个全新的message Test1的方式进行解析。
Optional and Repeated Elements
proto3默认全部字段都是Optional类型(其实是singular,具体区别见《Field Presence》相关内容)的,我们不需要在.proto文件中指定。optional的字段,编码起来是非常简单的,如果它不存在,我们直接不对其进行编码即可。解析端如果找不到这个字段的数据,则会赋予一个默认值。
对于repeated的字段,默认的编码方式是,有几个数据,字段名称就出现几次:
message Test4 {
optional string d = 4;
repeated int32 e = 5;
}
对e赋值多次,得到的结果是:
5: 1
5: 2
5: 3
字段e的各个赋值的顺序和存储顺序是严格一致的,而e与d的存储顺序是没有要求的。
如果我们对repeated的字段指定为packed形式,proto3是默认的。则会被编码为:
5: {1 2 3}
打包不是一定发生的,也可能会被编码为:
5: {1 2}
5: {3}
Last One Wins
对于一些非repeated的数据字段,如果在编码后的数据中出现多次,以最后一个实例为准。
Maps
其实Maps仅仅是repeated字段的其中一种表示形式:
message Test6 {
map<string, int32> g = 7;
}
实际会被表示为:
message Test6 {
message g_Entry {
optional string key = 1;
optional int32 value = 2;
}
repeated g_Entry g = 7;
}
Field Order
字段之间的相对顺序是无序的,解码器应当适应这种的情况。并且,同一个对象经过编码后,每次的二进制数据都不保证相同。
启示
这也就意味着:
- 每次编码得到的二进制数据不保证相同;
- 以下操作都不保证正确性:
foo.SerializeAsString() == foo.SerializeAsString() Hash(foo.SerializeAsString()) == Hash(foo.SerializeAsString()) CRC(foo.SerializeAsString()) == CRC(foo.SerializeAsString()) FingerPrint(foo.SerializeAsString()) == FingerPrint(foo.SerializeAsString()) - 新旧协议对同一个proto对象的编码方式也是不相同的。