sysfs属于伪文件系统,它始终需要mount 到 vfs(kernel 虚拟文件系统),响应vfs的接口,内核才能通过sysfs将信息传递给用户空间。
注册sysfs
sysfs初始化调用栈:
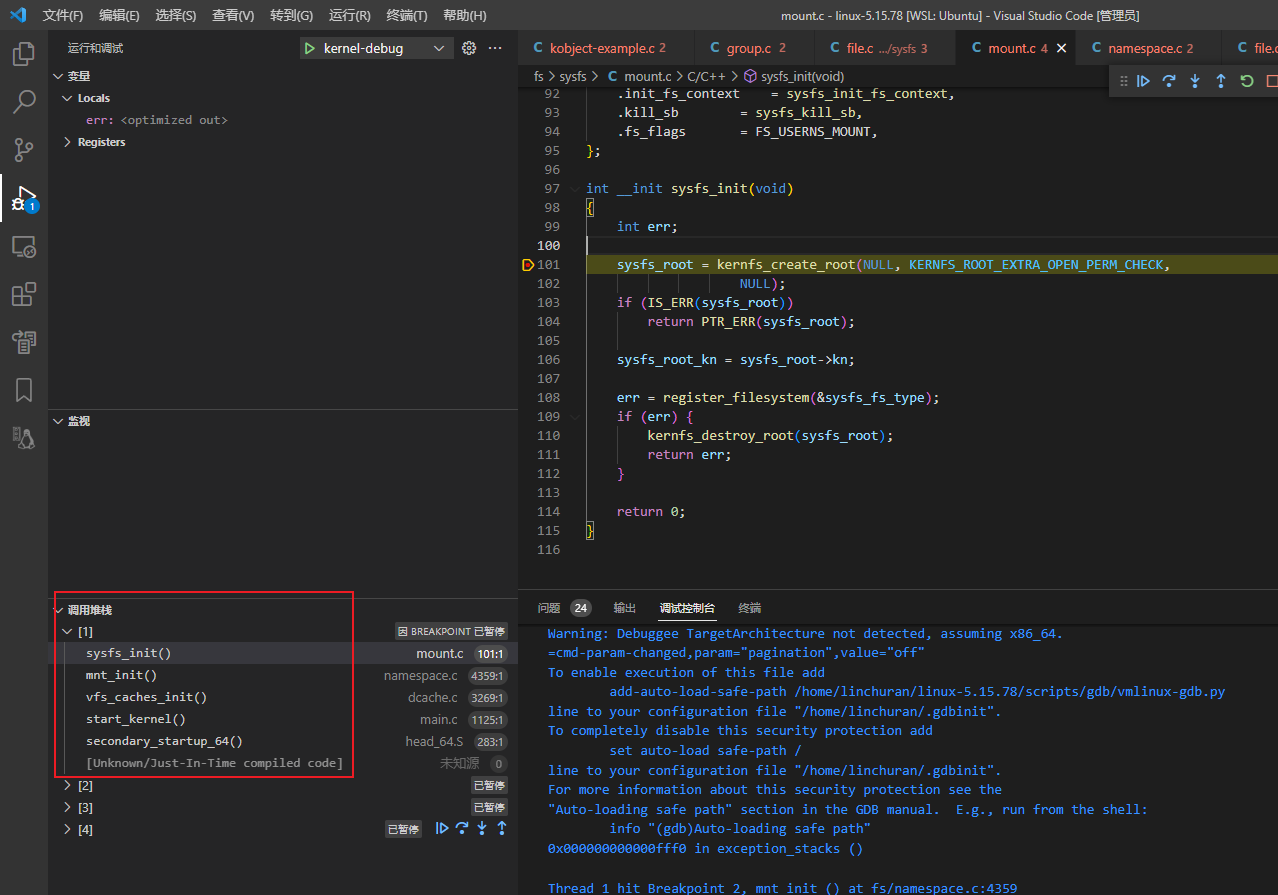
int __init sysfs_init(void)
{
sysfs_root = kernfs_create_root(NULL, KERNFS_ROOT_EXTRA_OPEN_PERM_CHECK,
NULL);
sysfs_root_kn = sysfs_root->kn;
err = register_filesystem(&sysfs_fs_type);
}
kernfs_create_root :创建kernfs_root,指定syscall_ops == NULL,并附带一个kernfs_node。
kernfs_root 赋值给 sysfs_root, kernfs_node赋值给sysfs_root_kn。
register_filesystem :将下面的文件系统结构体注册到vfs中。
static struct file_system_type sysfs_fs_type = {
.name = "sysfs",
.init_fs_context = sysfs_init_fs_context,
.kill_sb = sysfs_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
};
sysfs_init_fs_context 负责 mount 行为,查看其调用栈。
哦豁,没有发现 /sys 目录。。。
这是因为,没有触发sysfs挂载。以往,在sysfs_init函数中会自动挂载sysfs,现在需要特殊指定挂载。
挂载sysfs
回到《如何在主机端调试Linux内核》,在/etc/fstab中增加sysfs文件系统。
sysfs /sys sysfs defaults 0 0

期望的东西终于有了。
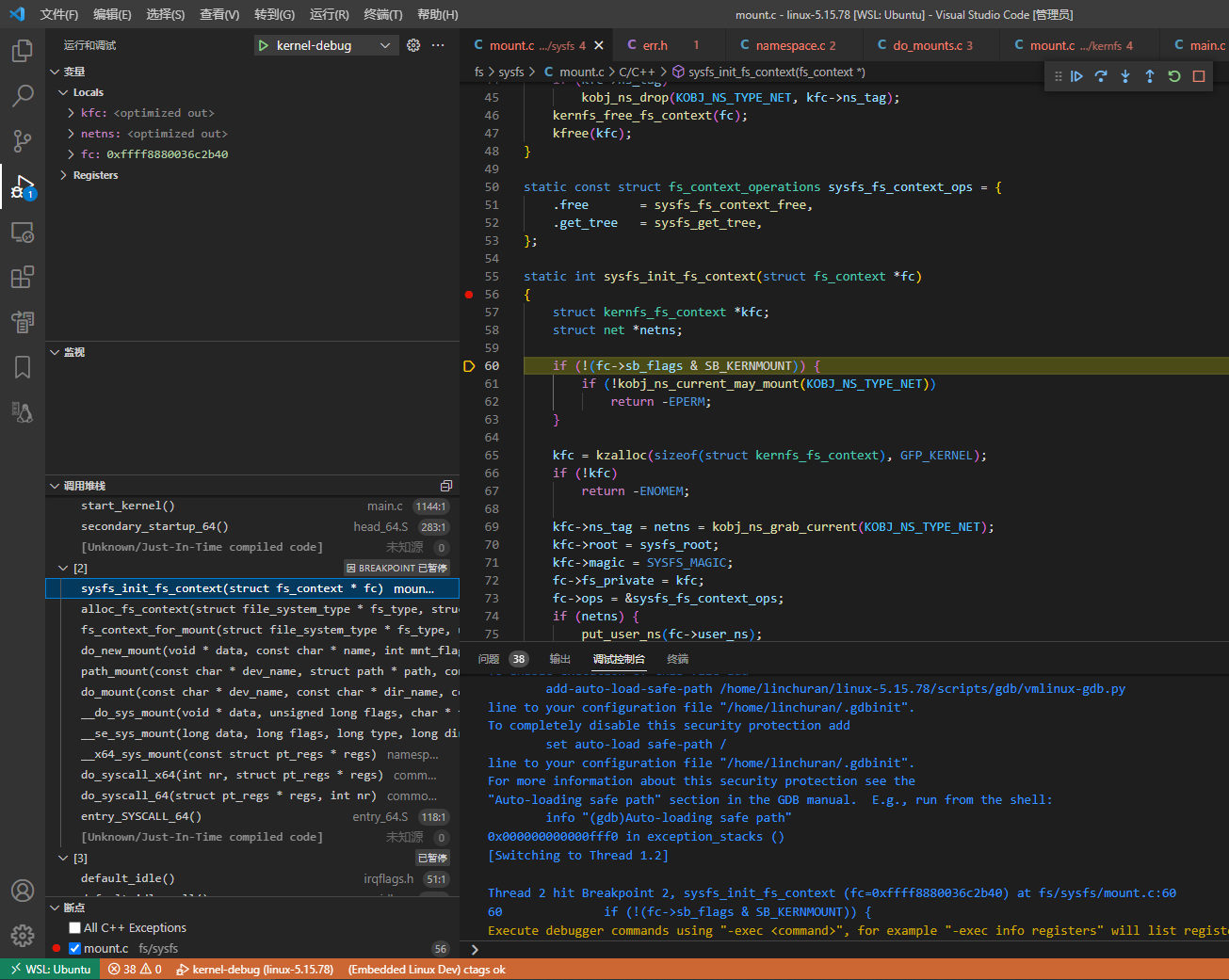
init进程解析 /etc/fstab,触发系统调用来挂载sysfs。
static int sysfs_init_fs_context(struct fs_context *fc)
{
struct kernfs_fs_context *kfc;
kfc->root = sysfs_root;
fc->fs_private = kfc;
fc->ops = &sysfs_fs_context_ops;
}
sysfs_fs_context_ops 涉及真正的文件系统,是VFS挂载sysfs的重点。
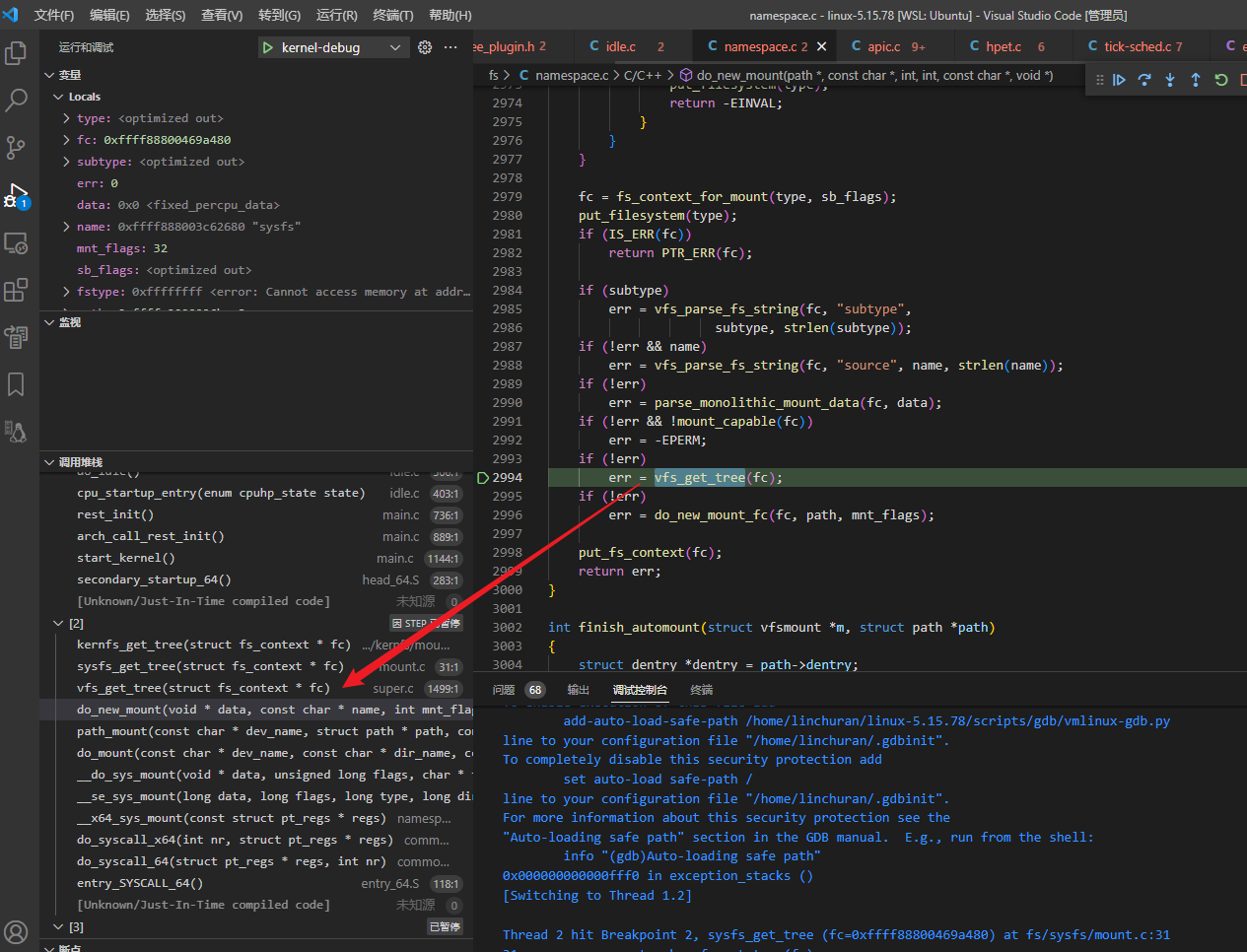
int kernfs_get_tree(struct fs_context *fc)
{
struct kernfs_fs_context *kfc = fc->fs_private;
struct super_block *sb;
struct kernfs_super_info *info;
int error;
info = kzalloc(sizeof(*info), GFP_KERNEL);
if (!info)
return -ENOMEM;
info->root = kfc->root;
info->ns = kfc->ns_tag;
INIT_LIST_HEAD(&info->node);
fc->s_fs_info = info;
sb = sget_fc(fc, kernfs_test_super, kernfs_set_super);
if (!sb->s_root) {
struct kernfs_super_info *info = kernfs_info(sb);
error = kernfs_fill_super(sb, kfc);
list_add(&info->node, &info->root->supers);
}
fc->root = dget(sb->s_root);
return 0;
}
文件系统组成:(盗图)
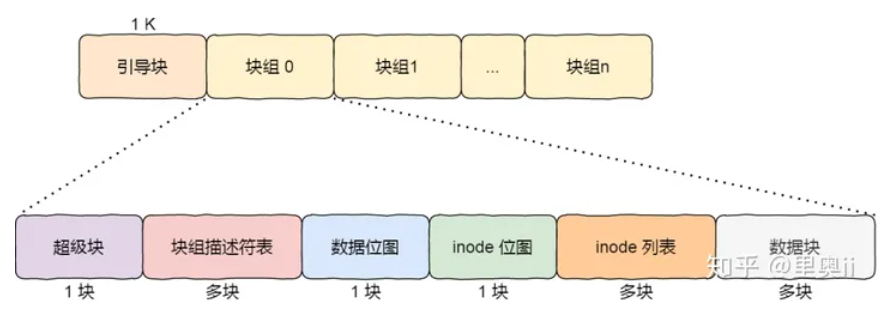
一个文件系统要跟vfs关联起来(mount),需要提供三个信息:超级块、根inode、根dentry。
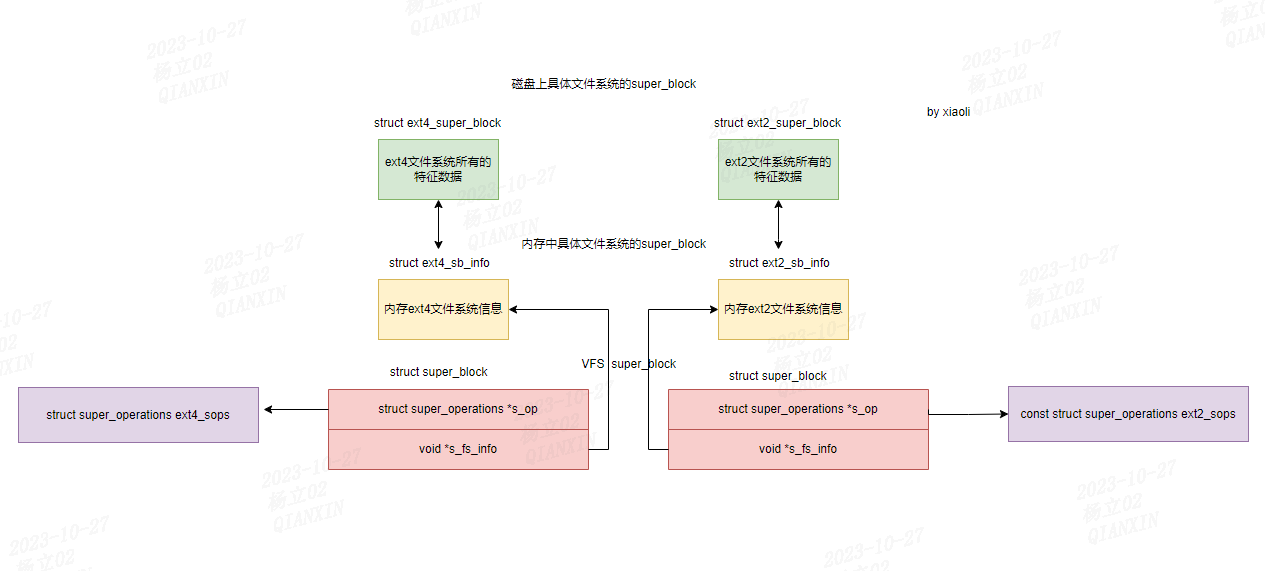
关于super_block,其实有三个super_block相关的数据结构:
- 磁盘上实际存储的super_block,需要读取到内存中
- 内存中文件系统的super_block info,描述了super_block的基本信息,使用指针指向磁盘中的super_block
- VFS的super_block,使用指针指向super_block info
以ext4文件系统为例:
磁盘上的super_block:
struct ext4_super_block {
/*00*/ __le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count_lo; /* Blocks count */
__le32 s_r_blocks_count_lo; /* Reserved blocks count */
__le32 s_free_blocks_count_lo; /* Free blocks count */
/*10*/ __le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
......
super_block info:
struct ext4_sb_info {
struct ext4_super_block *s_es; /* Pointer to the super block in the buffer */
vfs super_block:
struct super_block {
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
void *s_fs_info; /* Filesystem private info */
当挂载完成后,文件系统的关系图如下:
跟踪sysfs的super_block的填充过程,
static int kernfs_fill_super(struct super_block *sb, struct kernfs_fs_context *kfc)
{
struct kernfs_super_info *info = kernfs_info(sb);
struct inode *inode;
struct dentry *root;
info->sb = sb;
sb->s_op = &kernfs_sops;
inode = kernfs_get_inode(sb, info->root->kn);
root = d_make_root(inode);
sb->s_root = root;
sb->s_d_op = &kernfs_dops;
return 0;
}
三个要素(超级块、根inode、根dentry)即operator(s_op、s_d_op)都得到了。
那么,kernfs_node与inode必定存在某种关联:
static void kernfs_init_inode(struct kernfs_node *kn, struct inode *inode)
{
kernfs_get(kn);
inode->i_private = kn;
inode->i_mapping->a_ops = &ram_aops;
inode->i_op = &kernfs_iops;
inode->i_generation = kernfs_gen(kn);
switch (kernfs_type(kn)) {
case KERNFS_DIR:
inode->i_op = &kernfs_dir_iops;
inode->i_fop = &kernfs_dir_fops;
case KERNFS_FILE:
inode->i_size = kn->attr.size;
inode->i_fop = &kernfs_file_fops;
break;
case KERNFS_LINK:
inode->i_op = &kernfs_symlink_iops;
break;
default:
BUG();
}
至此,整个过程就完成了,在sysfs中,我们可以将kernfs_node当做inode来看待。
sysfs_ops
根据上面所赋予的inode的操作接口,可以继续往下追踪。
const struct file_operations kernfs_file_fops = {
.open = kernfs_fop_open,
};
在kernfs_fop_open里面,完成了sysfs_ops的关联,并在read/write函数中,从file里面找到private_data,最终找到kernfs_ops的show/store方法.
参考
https://zhuanlan.zhihu.com/p/191266693
https://blog.csdn.net/weixin_45030965/article/details/134076622